The cut command in Linux is a powerful text-processing utility used to extract specific sections from each line of a file or from piped input. It does not alter the original file but simply reads the content and displays the desired portions on the standard output. In this article, we’ll explore the purpose of the cut command in Linux and demonstrate how to use it through practical, real-world examples.
Understanding the cut Command
The cut command is a valuable tool for anyone working with structured text, enabling efficient data manipulation and extraction in Unix-like systems. It extracts parts of a line based on byte positions, character positions, delimiters, or fields. This makes it especially useful for filtering and organizing data in shell scripts and command-line operations. It’s also useful for tasks like retrieving columns from CSV files, trimming characters, or analyzing log files. Although it’s commonly used with files, the cut command can also process the output of other commands when used in a pipeline.
Basic Syntax of cut Command
The cut command has a very simple syntax that uses options and a file name. Here’s how it works:
cut [OPTIONS] [FILE]Here, OPTIONS lets you control how the cut command works. You can choose a field separator (like a comma), pick certain fields, set field ranges, ignore lines without the separator, etc. FILE is the target file from which you want to extract data. The cut command will read from the standard input if you don’t specify a file. Moreover, you can specify multiple files; in that case, the cut command will treat them as one by combining their contents before processing.
Commonly Used Options
The cut command lets you extract specific parts of text from a file or input. You can tell it what to extract using different options, such as bytes, characters, or fields, and by setting a specific separator (delimiter). Here are the common options:
- -f or –fields=LIST: Selects specific fields based on a chosen delimiter.
- -b or –bytes=LIST: Extracts certain bytes from each line.
- -c or –characters=LIST: Pulls out specific characters from each line.
- -d or –delimiter: Sets a custom delimiter instead of the default tab.
- –complement: Shows everything except the selected fields, bytes, or characters.
- -s or –only-delimited: Skips lines that don’t have the delimiter. By default, such lines are included.
- –output-delimiter: It lets you choose a different delimiter for the output. By default, cut uses the same delimiter as the input.
The -f, -b, and -c options use a LIST to define what to extract, such as fields, bytes, or characters. You can specify the following:
- A single number like 2
- Multiple numbers separated by commas, like 1,3,5
- A range like 2-4 (meaning extract from 2 to 4)
N-to mean from position N to the end-Mto mean from the start-up to position M
How the cut Command Works in Linux
Let’s go through some practical examples to understand how the cut command works in Linux. For this purpose, first, create a file called “mte.csv” using the echo command:
echo -e "empID,empName,empDesig\n101,Anees,Author\n102,Asghar,Manager\n103,Damian,CEO" > mte.csv
Let’s verify the file’s content using the cat command:
cat mte.csv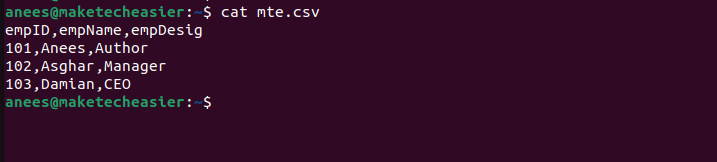
Here, it’s important to note that the cut command doesn’t change the file, instead, it just shows selected output based on what you ask.
Extracting Data By Characters
Use the -c option along with the cut command to extract characters by position:
cut -c 1,8 mte.csvThis command extracts the first and eighth characters from each row:

To extract characters between specific positions or ranges, we can use the cut command as follows:
cut -c 1-8 mte.csvThis command extracts the eighth characters (between 1 and 8) from each row:

Extracting By Byte
We can use the -b option with the cut command to extract specific bytes from each line:
cut -b 1-3 mte.csvThis command extracts the first three bytes from each line of the file named mte.csv:

Extracting By Field (Column)
You can extract an entire field of a file using the cut command. To do this, use the -f with -d option, as follows:
cut -d',' -f2 mte.csvIn this command, -d',' sets the delimiter to a comma, and -f2 tells cut to extract the second field from each line in the mte.csv file:

Using Custom Delimiters in cut
The cut command uses a tab as a delimiter, by default. However, if your fields are separated by something other than a tab, use -d to set the right one. For example, we can get the fifth word from a space-separated sentence using the -d delimiter as follows:
echo "Hey! Geeks Welcome to Maketecheasier.com" | cut -d ' ' -f 5
Skipping Certain Fields During Extraction
You can exclude specific fields while extracting text from a file by using the --complement option with the cut command. This option instructs the cut command to output all fields except the specified ones:
cut -d',' -f1 mte.csv --complementThis command will skip the first column and return the rest of the content:

Changing the Default Delimiter in Output
By default, the cut command preserves the input delimiter in the output when extracting fields. However, you can change the output delimiter using the --output-delimiter option when working with field-based extraction:
cut -d',' -f1-3 --output-delimiter='-' mte.csvThis command uses the hyphen - as a separator in the output:

Using cut with Other Useful Linux Commands
You can also use cut with other Linux commands using the pipeline symbol. For example, the following command extracts the first 5 characters from each line of the who command’s output:
who | cut -c 1-5
In the following example, we use the cut command along with head to display the first two lines of the “mte.csv” file and extract only the empName and empDesig fields:
head -n 2 mte.csv | cut -d ',' -f2,3
Managing Irregular Data Formats with Linux cut Command
The cut command works best when the data is neatly organized, with the same delimiter (like a comma or tab) separating each part. But if the file has uneven spaces or mixed delimiters, cut might not work well on its own. In such situations, it’s useful to first clean up the data using commands like tr or sed to make sure cut can extract the right parts.
Handling Extra Spaces
Consider a file named “mteData.txt” where fields are separated by multiple spaces, as shown below:
cat mteData.txt
Since cut expects a single, consistent delimiter, we can simplify the spacing using tr before applying cut:
cat mteData.txt | tr -s ' ' | cut -d ' ' -f1-2This command reads the content of “mteData.txt”, uses tr to replace multiple spaces with a single space, and then uses cut to extract the first two fields separated by space:

Handling Mixed Delimiters
If a file uses a combination of spaces and commas as delimiters, we can normalize the format using sed. For example, a file named “mteData1.txt” contains the following content:
cat mteData1.txt
Let’s use the sed command with the cut command to replace all spaces with a comma and then extract the first and third comma-separated fields:
sed 's/ /,/g' mteData1.txt | cut -d ',' -f1,3
Wrapping Up
In this article, we explored the Linux cut command, a useful command in Linux for extracting data from files or piped input. With its simple syntax, you can easily get characters, bytes, or fields based on a delimiter. We also demonstrated how to use the cut command with other commands like tr, sed, and head to manage messy data and simplify the output. Whether you’re working with CSV files, analyzing logs, or cleaning up data, the cut command is a must-have tool for text processing on Unix-like systems.